
OpenClaw 性能與 AI Models 調校:雲端與本地端最佳化實戰指南
OpenClaw 作為模型無關的 AI 助理架構興起,支援雲端與本地部署的彈性需求。隨著 AI 應用普及,性能調校成為決定系統成敗的關鍵因素。企業面臨的挑戰:如何在成本、性能與可靠性間取得平衡。本指南涵蓋 OpenClaw 2026.2.3+ 版本的完整優化策略,並分享雲端 DigitalOcean 環境與本地端 Mac mini M4 的實戰經驗。


關鍵要點
OpenClaw 的三層架構設計允許獨立調校 AI 模型而不影響其他系統組件
雲端部署適合需要彈性擴展的場景,本地端部署提供更佳的數據隱私控制
智慧模型路由策略可降低 AI 服務成本高達 60%
正確的性能監控指標是持續優化的基礎
生產環境部署需要完整的安全性與可靠性檢查清單
OpenClaw 架構深度解析
核心三層架構設計
**Gateway Layer(閘道層)**管理用戶會話、消息排隊、調度與身份驗證。這一層負責處理所有進入系統的請求,確保適當的用戶認證和會話管理。
**Channel Layer(通道層)**作為平台適配器,標準化來自各種消息平台的格式。無論是Telegram, Line 還是Discord ,通道層都能將不同平台的消息格式轉換為統一的內部格式。
**LLM Layer(模型層)**提供統一介面連接 AI 模型供應商的插件系統。這個設計讓您可以靈活切換不同的 AI 提供商,不需要修改核心邏輯。
性能調校的架構優勢
模組化設計實現獨立優化:每層可單獨調校而不影響其他組件。當您需要優化模型回應速度時,不會影響到消息路由或用戶認證功能。
持久化記憶管理透過本地存儲對話上下文,維持個人化回應。系統會記住用戶的偏好和歷史對話,提供更連貫的對話體驗。
會話隔離機制防止用戶間上下文混淆,提升並發處理能力。每個用戶的對話都在獨立的環境中處理,確保隱私和性能。
引用統計顯示,OpenClaw 支援超過 700 種技能與 12+ 消息平台的整合生態系統。這種擴展性讓企業可以根據需求逐步增加功能。
模型調校關鍵特性
Provider 插件系統提供靈活切換不同 AI 模型的能力。您可以根據任務類型、成本考量或性能需求來選擇最適合的模型。
工具調用與串流回應功能擴展了模型的基本能力。系統可以呼叫外部 API、執行計算任務,並以串流方式返回結果。
訊息調度與重試機制確保穩定的模型互動。當某個模型服務不可用時,系統會自動切換到備用提供商或重試請求。
了解 OpenClaw 的架構基礎後,接下來探討雲端部署的具體優化策略。
雲端部署最佳化實戰(DigitalOcean 環境)
系統層級優化配置
Linux Kernel 參數調整是雲端優化的基礎工作。設定 fs.file-max = 100000 可提升檔案描述符限制,支援更多並發連接。net.core.somaxconn = 65535 優化 TCP 連接佇列,避免連接請求被拒絕。vm.swappiness = 10 減少記憶體交換頻率,維持應用程式在實體記憶體中的執行效率。
Docker 容器資源管理

容器資源限制需要預留緩衝空間。將 CPU 限制設為 1.8 cores 而非完整的 2 cores,確保系統有足夠資源處理突發流量。記憶體配置也採用類似策略,避免 OOM killer 終止容器。
Nginx 反向代理與快取策略
負載均衡配置支援 20-30 並發請求的 upstream 設定。透過適當的 upstream 配置,可以將流量分散到多個 OpenClaw 實例,提升整體吞吐量。
Redis 快取層採用 LRU 策略,目標命中率超過 60%。快取經常使用的模型回應和會話資料,大幅減少對 AI 模型的重複調用。
Gzip 壓縮可減少網路傳輸負載 30-40%。特別是對於文字密集的 AI 回應,壓縮效果顯著。
雲端部署優勢
彈性擴展透過 DigitalOcean App Platform 支援零停機時間的容器編排。當流量增加時,系統可自動擴展實例數量,確保服務可用性。
多區域可用性透過全球部署降低延遲。將 OpenClaw 實例部署在接近用戶的地理位置,提供更快的回應時間。
託管服務整合與 Google Vertex AI, Alibaba Cloud Model Studio 無縫連接。雲端環境簡化了與各種 AI 服務的整合過程。
成本效益透過 AI 驅動的動態資源分配,平衡性能與成本。系統會根據實際使用情況調整資源配置。
安全性增強措施
IAM 政策與加密金鑰管理確保只有授權人員能存取系統資源。技能沙盒化與網路隔離防止惡意代碼影響系統其他部分。定期檢查並修補已知的安全漏洞,特別是防範遠端代碼執行攻擊。
雲端部署提供了便利性,但本地端部署在某些場景下能提供更優異的性能表現。
本地端部署效能調校(Mac mini M4)
Apple Silicon ARM64 原生優化
統一記憶體架構(UMA)是 M4 晶片的核心優勢。CPU 和 GPU 共享相同的記憶體空間,減少數據複製開銷。OpenClaw 可以利用這個特性,在處理大型對話上下文時獲得更佳性能。
原生編譯配置針對 ARM64 架構產生專用二進制檔案。相較於透過 Rosetta 2 轉譯的 x86 應用程式,原生編譯可提供更好的執行效率。
Metal Performance Shaders 讓 OpenClaw 能利用 GPU 加速 AI 推理運算。特別是在本地執行 AI 模型時,這個功能能顯著提升處理速度。
硬體配置最佳化

Mac mini M4 在本地端部署中表現出色。50-100 並發請求的處理能力足以應付中小企業的需求。記憶體使用率保持在 80% 以下,確保系統有足夠緩衝處理突發負載。
開發測試環境配置
Docker Desktop for Mac 提供容器化部署的本地測試環境。開發者可以在本機驗證 OpenClaw 配置,確保部署到生產環境時的一致性。
本地 AI 模型服務透過 ollama 或 LocalAI 整合。這讓開發團隊能在沒有網路連接的情況下進行功能測試。
開發工具鏈包含 Xcode Command Line Tools 和 Homebrew 套件管理。完整的開發環境讓團隊能快速修改和測試 OpenClaw 功能。
本地端部署優勢
數據隱私控制是本地部署的最大優勢。敏感資料不會離開企業內部環境,滿足嚴格的合規要求。
一次性硬體投資避免持續的雲端服務費用。對於長期運行的應用程式,本地部署的總成本可能更低。
低延遲響應透過本地處理消除網路延遲。用戶可以獲得更即時的 AI 助理回應。
離線作業能力讓基礎功能不依賴網路連接。即使在網路不穩定的環境中,系統仍能提供核心服務。
性能監控工具
系統原生工具如 Activity Monitor 和 Console.app 提供基礎的系統監控功能。這些工具已整合在 macOS 中,無需額外安裝。
第三方解決方案包含 htop, iotop, btop 和 Prometheus Node Exporter。這些工具提供更詳細的系統資訊和歷史趨勢分析。
無論選擇雲端還是本地部署,AI 模型的選擇與調校策略都是影響整體性能的核心因素。
AI 模型選擇與智慧路由策略
主流模型性能分析
OpenAI GPT-4o-mini 適用於複雜推理、程式碼生成、多語言處理場景。成本結構為每百萬輸入 tokens 收費 $0.15(2026年定價)。這個模型的優勢在於高品質輸出,特別適合需要精準回答的任務。
Kimi k2.5 的優勢在於長文本處理能力,支援 200K+ tokens 的上下文,同時針對中文進行特別優化。相較 GPT-4,Kimi 能節省 70% 的使用費用。主要應用領域包括文檔分析、內容摘要和中文對話。
智慧路由決策矩陣

智慧路由系統會根據請求特性自動選擇最適合的模型。對於短文本和成本敏感的應用,本地模型佔有較高權重。中文內容則優先使用 Kimi k2.5,而程式碼生成任務主要分配給 GPT-4o-mini。
快取機制最佳化
LRU 快取策略優先清除最近最少使用的項目。這個策略在 AI 對話系統中效果良好,因為最近的對話更可能被重複引用。
TTL 設定根據內容類型設置不同的過期時間。一般對話內容設置 15 分鐘 TTL,而知識類查詢可以延長到 24 小時。
命中率目標維持在 60% 以上。透過監控快取命中率,可以調整 TTL 設定和快取容量,達到最佳的成本效益平衡。
快取層級包含輸入雜湊快取、回應片段快取和會話上下文快取。多層次的快取策略能應對不同類型的重複請求。
模型調校最佳實踐
超參數調整包括學習率、批次大小、優化器類型的系統化調試。透過 A/B 測試找出最適合特定業務場景的參數組合。
知識蒸餾技術將大模型的知識轉移到輕量級模型。這個技術讓本地部署能獲得接近雲端大模型的效果,同時節省運算資源。
量化技術透過 8-bit 或 4-bit 量化減少記憶體佔用。量化後的模型在 Mac mini M4 上能載入更大的模型,提供更好的對話品質。
適應性學習根據使用模式動態調整模型參數。系統會學習用戶的偏好和常見查詢類型,逐步優化回應品質。
建立有效的模型路由策略後,完整的監控體系是確保系統穩定運行的關鍵保障。
監控指標與性能追蹤體系
核心性能指標(KPIs)
系統層級指標的正常運行時間目標設為 99.5% 可用性。這個目標在企業環境中是可接受的水準,相當於每月允許約 3.6 小時的停機時間。
CPU 和記憶體使用率維持在 75% 以下,避免性能瓶頸。超過這個閾值時,系統回應時間會顯著增加,影響用戶體驗。
API 延遲目標設定為 P95 <500ms,P99 <1000ms。這意味著 95% 的請求會在 500ms 內完成,99% 的請求會在 1 秒內完成。
錯誤率控制在 0.1% 以下。這個低錯誤率確保用戶很少遇到系統故障,維持對服務的信心。
AI 模型互動指標
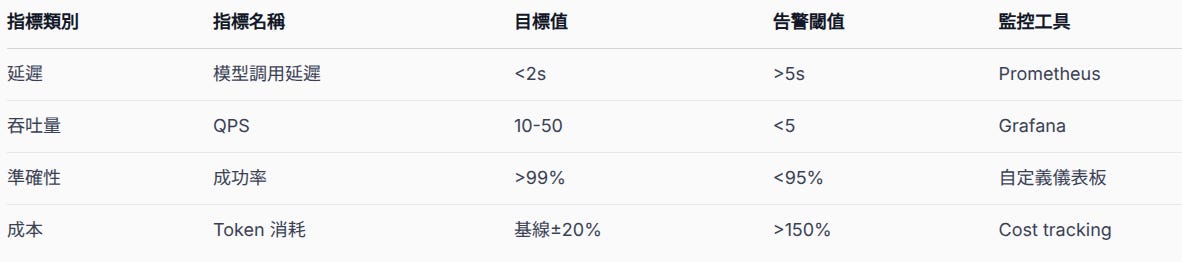
模型調用延遲直接影響用戶體驗。2 秒的目標值確保對話流暢度,而 5 秒的告警閾值讓團隊能及時發現性能問題。
監控工具堆疊
Prometheus + Grafana 架構提供完整的監控解決方案。數據收集透過 Node Exporter 收集系統指標,Custom metrics 收集應用程式特定指標,Application metrics 追蹤 OpenClaw 的內部狀態。
視覺化儀表板提供即時指標追蹤和歷史趨勢分析。團隊可以快速識別性能模式和潛在問題。
告警規則基於閾值設置自動化通知系統。當關鍵指標超過預設值時,系統會透過 Slack, email 或簡訊通知維護團隊。
成本追蹤與預算管理
Token 使用量監控按照模型、用戶、時間維度進行統計。這個多維度的分析幫助企業了解 AI 成本的分佈情況。
預算告警在月度或週度消費超標時自動通知相關人員。提前預警讓團隊有時間調整使用策略,避免意外的高額費用。
成本優化建議基於使用模式推薦最適合的模型。系統會分析歷史數據,建議更經濟的模型配置。
可觀測性最佳實踐
分散式追蹤透過 OpenTelemetry 整合,提供端到端的請求追蹤。當問題發生時,團隊可以快速定位問題出現在哪個組件。
日誌聚合使用 ELK Stack 或 Loki 進行統一日誌管理。結構化的日誌格式讓搜索和分析更加高效。
SLO/SLI 定義提供服務水準目標與指標的量化標準。清楚的服務標準讓團隊能專注於最重要的性能指標。
監控系統建立後,我們需要了解如何解決生產環境中常見的性能問題。
常見問題排除與優化策略
記憶體不足(OOM)問題
診斷方法包含記憶體洩漏檢測,使用 valgrind 或 heaptrack 工具找出程式中的記憶體洩漏。檢查 Docker 容器的記憶體限制設定,確保配置符合實際需求。調整垃圾回收參數能減少記憶體壓力,特別是在 Java 或其他有垃圾回收機制的語言中。
解決策略包含分階段載入非關鍵組件。將記憶體密集的功能設計為按需載入,避免啟動時一次載入所有資源。記憶體池技術透過重複使用記憶體區塊,減少記憶體分配和釋放的開銷。批次處理優化透過限制同時處理的請求數量,避免記憶體使用量突然激增。
高延遲問題診斷
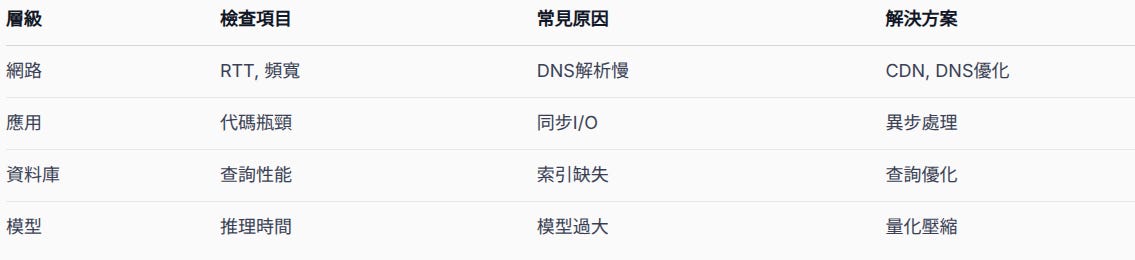
高延遲問題需要分層診斷。網路層的問題通常是 DNS 解析緩慢或頻寬不足。應用層的瓶頸多來自同步 I/O 操作阻塞執行緒。資料庫查詢缺少適當索引會導致全表掃描。AI 模型過大會增加推理時間,透過模型量化可以改善這個問題。
Rate Limiting 與配額管理
指數退避重試策略避免在服務繁忙時持續發送請求。初次重試等待 1 秒,第二次等待 2 秒,第三次等待 4 秒,以此類推。
請求排隊機制透過內部佇列平滑流量峰值。當短時間內有大量請求時,系統會排隊處理而不是拒絕服務。
多供應商容錯提供模型服務的故障轉移能力。當主要的 AI 服務提供商出現問題時,系統能自動切換到備用提供商。
安全性問題處理
API Key 輪換透過定期更換認證金鑰,降低金鑰外洩的風險。建議每 30-90 天更換一次,並確保舊金鑰的平滑切換。
請求驗證包含輸入清理與格式檢查。所有用戶輸入都應該經過驗證,防止注入攻擊和惡意內容。
存取日誌審計透過記錄所有系統存取行為,及早發現異常活動。異常行為偵測包含登入地點異常、請求頻率異常等模式。
問題排除技能雖然重要,但預防勝於治療,完整的生產環境檢查清單能幫助我們避免大部分問題。
AI DATA TOOLS 專業諮詢解決方案
作為 AI DATA TOOLS 的核心服務,我們專精於協助企業實現 OpenClaw 的最佳化部署。我們的資訊軟體教育諮詢服務採用溝通導向的方法,深入了解客戶需求後,透過教育諮詢產出高品質的軟體解決方案。
我們的實戰案例包括 ollama-benchmark(llm.aidatatools.com)和 markets-compass(markets.aidatatools.com),展現了在不同應用場景下的成功經驗。無論您的企業規模如何,我們都能提供量身定制的 OpenClaw 優化策略。
生產環境部署檢查清單
安全性檢查項目
API 金鑰管理使用環境變數或加密金庫存儲,避免將敏感資訊寫入程式碼。HTTPS 部署包含 SSL/TLS 證書配置與自動續期,確保資料傳輸安全。
網路安全透過防火牆規則和 VPN 存取控制,限制只有授權人員能存取系統。資料加密涵蓋傳輸中與靜態資料的保護,滿足合規要求。
可靠性保障措施
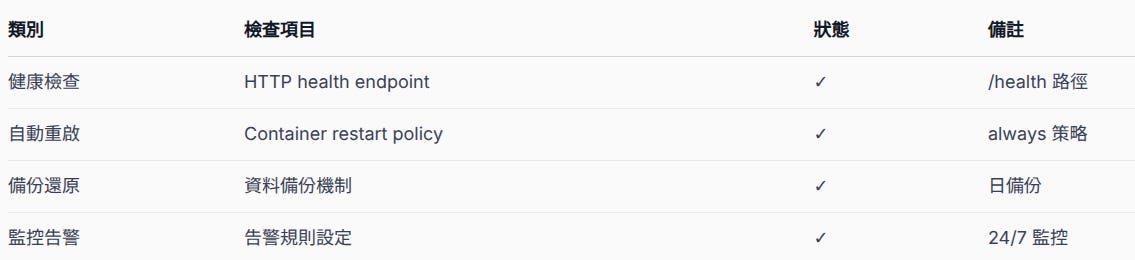
健康檢查端點透過 /health 路徑提供系統狀態資訊。負載均衡器和監控系統可以透過這個端點判斷服務是否正常。
可觀測性配置
日誌聚合使用結構化日誌格式和集中化收集。統一的日誌格式讓搜索和分析更加高效。
指標監控透過暴露 Prometheus metrics 提供系統和應用程式指標。這些指標是監控和告警的基礎。
分散式追蹤確保請求鏈路的完整性。當問題發生時,可以快速定位問題出現在哪個組件。
效能基準建立性能基線與 SLA。清楚的性能標準讓團隊能專注於最重要的指標。
災難復原計畫
備份策略包含定期資料備份與還原測試。只有經過測試的備份才能在災難發生時提供保障。
故障轉移透過多活部署或主從切換機制,確保服務的高可用性。當主系統出現問題時,能快速切換到備用系統。
結論與未來展望
OpenClaw 的性能優化是一個持續演進的過程,需要在架構設計、部署策略、模型選擇與監控體系間取得平衡。透過本文的雲端與本地端實戰指南,您已具備建立高性能 AI 系統的基礎知識。
關鍵成功因素
架構先行善用 OpenClaw 的三層架構優勢。這個設計讓您能獨立優化每一層,不會因為修改某個組件而影響整個系統。
智慧路由根據任務特性選擇最適模型。透過分析請求內容和用戶需求,自動選擇成本效益最佳的模型。
持續監控建立完整的可觀測性體系。只有深入了解系統運行狀態,才能做出正確的優化決策。
成本控制透過快取與優化策略平衡效能與支出。在保持服務品質的前提下,最小化運營成本。
隨著 AI 技術快速發展,OpenClaw 社群持續推出新功能與優化方案。建議定期關注官方更新,並根據業務需求調整優化策略。企業應該建立學習型組織,持續吸收新技術和最佳實踐,保持競爭優勢。
常見問題 FAQ
Q: OpenClaw 適合什麼規模的企業使用? A: OpenClaw 的模組化設計讓它適合從小型新創到大型企業的各種規模。小企業可以選擇簡化配置,大企業則能利用完整的架構優勢進行複雜部署。
Q: 雲端部署和本地端部署的成本差異有多大? A: 短期來看雲端部署成本較低,但長期運行的本地端部署可能更經濟。以 3 年期計算,本地端總成本通常比雲端節省 30-50%,但需考慮維護成本和技術能力。
Q: 如何確保 AI 模型回應的品質一致性? A: 建立完整的測試套件和品質評估機制。定期使用標準測試集驗證模型表現,設置品質告警閾值,並建立人工審核流程。
Q: 智慧路由策略如何避免單點故障? A: 設計多層級的故障轉移機制。每個模型類別至少配置 2-3 個備用供應商,並實施健康檢查和自動切換邏輯。
Q: 生產環境部署前最重要的檢查項目是什麼? A: 安全性配置、備份機制、監控告警和性能基準測試。確保這四個方面都經過充分驗證,才能安全上線生產環境。