NVIDIA CUDA 13.1:GPU程式設計的變革者
二十年來,NVIDIA 一直引領 GPU 運算領域。但大多數更新只是小幅改進,CUDA 13.1 卻截然不同。它徹底改寫了規則。此版本發布於 2025 年 12 月 4 日。


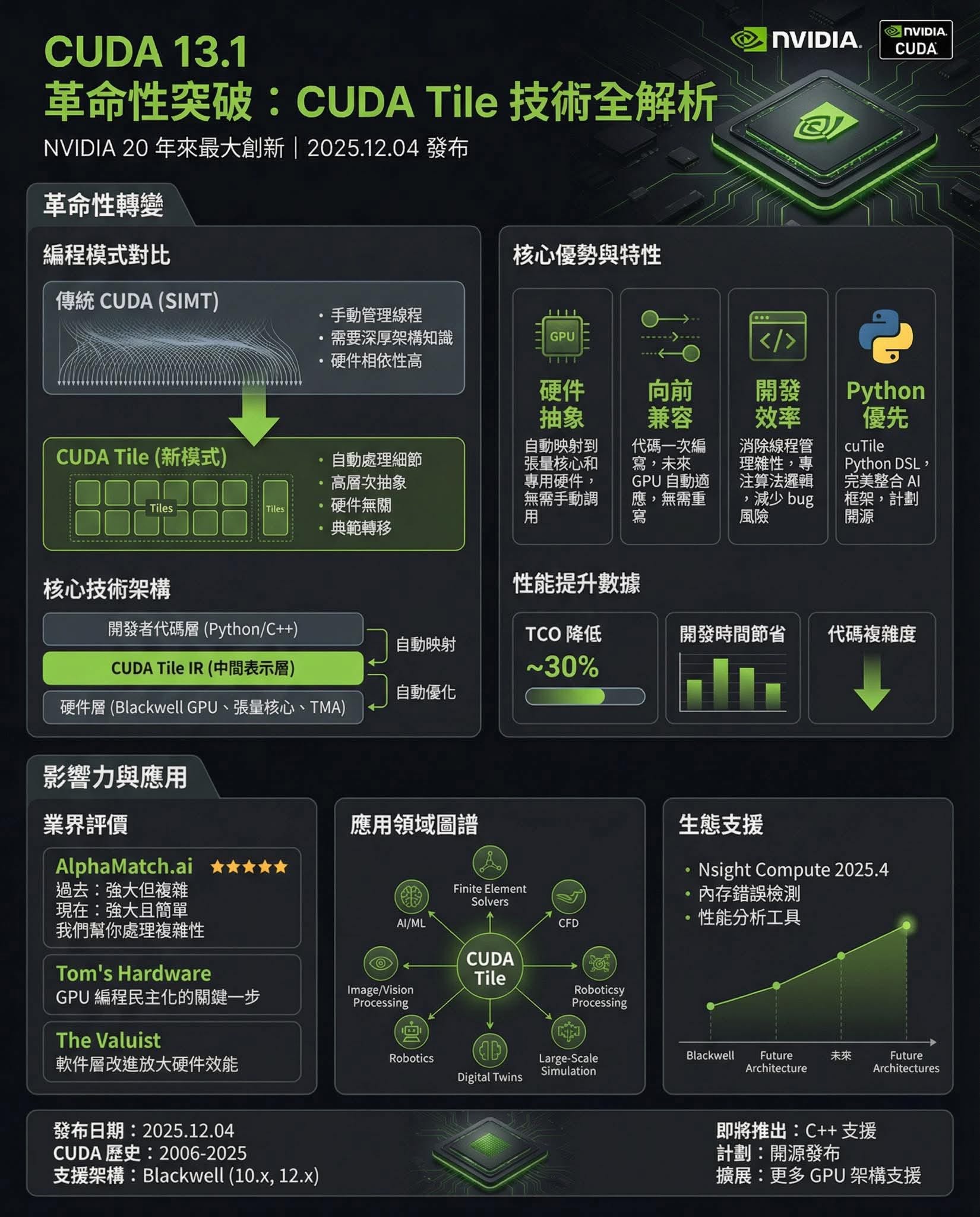
如果你嘗試過GPU編程,你就會知道這有多令人頭痛。你通常需要手動管理線程和記憶體等複雜細節。 CUDA 13.1引入了一項名為CUDA Tile的新技術,讓你可以專注於演算法本身,而無需操心硬體配置。
這次更新對開發者、資料科學家和人工智慧的未來意義重大,原因如下。
1. 重大轉變:從線程到圖塊
要了解 CUDA 13.1 的特殊之處,你必須看看我們過去是如何做事的。
舊方法(SIMT):你必須將資料分解成微小的線程和資料塊。你必須精細地管理記憶體存取。它功能強大,但難度大且脆弱。
新方法(CUDA Tile):現在,您不再管理單一線程,而是管理「Tile」(本質上是資料區塊)。
可以把它想像成從手排換成自動擋。你告訴系統“處理這部分資料”,CUDA 編譯器就會找出將其映射到硬體(Tensor Core、線程束等)的最佳方式。這樣你就能獲得強大的運算能力,而無需進行繁瑣的管理。
2. 你終於可以用 Python 寫高效能核心了
這項功能一定會讓數據科學家們歡呼雀躍。 NVIDIA 即將推出cuTile,一種基於 Python 的語言。
以前,要想獲得頂尖的GPU效能,你必須精通C++。而有了cuTile,你可以直接用Python寫GPU核心。系統會自動處理繁重的計算工作-並行化、調度和記憶體遷移。
它顯著降低了入門門檻。你可以用 Python 快速進行實驗,但程式碼會被編譯成與原生硬體程式碼一樣快的運行速度。
3. 讓你的程式碼面向未來
GPU 程式設計中最大的痛點之一是,針對某一代顯示卡最佳化的程式碼可能會導致其在下一代顯示卡上運作不佳。
CUDA 13.1 透過CUDA Tile IR(中間表示)解決了這個問題。本質上,您是針對“虛擬”架構編寫程式碼。當新的 GPU 發佈時,NVIDIA 會更新編譯器,您現有的程式碼會自動針對新硬體進行最佳化。您無需在每次發布新晶片時都重寫應用程式。
4. 人工智慧和科學的巨大進步
這次更新不僅是為了提高易用性,更是為了提升速度。
對於人工智慧/機器學習:全新的「Tile」方法非常適合人工智慧所需的數學運算(例如線性代數和張量運算)。在新一代 Blackwell GPU 上,這可以使複雜模型的效能提升 4 倍。
科學研究方面:從事物理模擬或量子化學的研究人員現在可以編寫更易於維護且運行速度更快的程式碼。一個研究小組發現,切換到新系統後,他們的模擬批次時間縮短了 40%。
5. “混合”方法
擔心舊代碼?不必擔心。
NVIDIA 將 CUDA 13.1 設計得非常實用。您無需重寫整個程式碼庫。您可以保留舊的 (SIMT) 程式碼來處理應用程式中複雜、繁瑣的部分,而使用新的 (Tile) 程式碼來處理繁重的計算任務。它們可以在同一個應用程式中完美共存。
6. 關鍵點:硬體需求
需要注意的一點限制是:CUDA Tile 目前需要 NVIDIA 最新的 Blackwell GPU。
如果您使用的是較舊的硬件,仍然可以使用標準的 CUDA 功能,但新的 Tile 功能是專為下一代基礎架構設計的。這是 NVIDIA 的一項策略性舉措,旨在為其最新、最強大的晶片建構「軟體護城河」。
7. NVIDIA 最新 Blackwell GPU 型號列表
NVIDIA RTX 50 系列消費性遊戲顯示卡
NVIDIA B200 Tensor Core GPU
NVIDIA B100 Tensor Core GPU
NVIDIA GB200 Grace Blackwell Superchip
概括
CUDA 13.1 解決了高效能運算領域最大的問題:能夠編寫深度底層 GPU 程式碼的工程師短缺。
透過抽象化複雜性,NVIDIA 讓開發者能夠更快、更輕鬆地工作。無論您是在訓練龐大的 Transformer 模型,還是運行量子化學模擬,CUDA 13.1 都能讓您專注於想要解決的問題,而不是晶片如何解決問題。
參考